
Sam Schifman
Chief Architect
When it comes to healthcare interoperability, FHIR (Fast Healthcare Interoperability Resources) is the wave of the future. From support by major EHR vendors to callouts in government mandates, FHIR has clearly made its mark and is here to stay. And there is good reason for it; FHIR breaks healthcare data into manageable chunks that can easily be exchanged with other systems. It provides a standard for RESTful APIs that enables access to data as specified by the United States Core Data for Interoperability (USCDI), along with other healthcare data, via a standard JSON or XML format. These standardized chunks, called FHIR resources, are extensible, providing the flexibility to meet many needs. Also, the associated APIs are rich enough to allow complex querying of the data. All of this provides a powerful tool to improve healthcare interoperability.
At Diameter Health we are thrilled to see this new standard blossom. It provides the structure to allow clinical data to flow and empower the healthcare of tomorrow. However, structural standardization is only half the equation. There is also a need for semantic standardization to unlock the true potential of clinical data. At Diameter Health we specialize in providing semantically normalized, enriched, and re-organized clinical data at scale. To normalize clinical data, it is often necessary to translate it. For example, one system may send an ICD-10 where a downstream system expects SNOMED. In other situations, the code may be missing entirely or have a blank description, which makes downstream use impossible. Correcting these problems may be required for compliance with the FHIR standard, but is also key to making the data actionable downstream and driving analytics. However, this raises the important question of traceability or data provenance: how can we ensure that the original data is available for audit and compliance purposes?
Here at Diameter Health we spend a lot of time thinking about this problem. We have explored many alternatives and looked at diverse ways FHIR can be extended. We believe we have arrived at an elegant solution to the problem, and we would like to share that with you.
FHIRing at the Target
Let’s start by clearly laying out the problem we set out to solve. Incoming clinical data, either in HL7v2, C-CDA, or FHIR, contains many codes and values. As we normalize these codes and values, we may need to do things like, but not limited to:
- Translating from one code system to another
- Providing or standardizing display names
- Ensuring correct units are applied to value
As we normalize, traceability is important. It is critical that we make it possible for customers to review the original codes and values sent as part of the original document. But we are subject to some constraints:
- We want all original codes and values available in a consistent way
- We don’t want to add confusion or bloat to the data
- We want to mitigate the cost of storing both original and new data
Spreading Wild FHIR
FHIR is an extensible model. It is possible to add extensions to any FHIR object. These extensions can be registered and follow predefined standards for data-types and structure. At first glance this would be a natural fit for storing and presenting original values. However, we found that extensions fall short on all three of our constraints.
Extensions would not be consistent.
While there are clear standards for extensions, not all FHIR resources have the same sets of codes and values. This design requires associating the right original code/value with the right element within the resource. This means either: 1) burying the extension deep in the codes and values or 2) creating an extension per element. Neither of these alternatives make it easy to access the data consistently.
Extensions add bloat.
By adding extensions to each resource, we double the data we are storing per resource. This price is paid both in storage and in bytes on the wire. Most uses of the data do not require both original and new, but everyone must pay this cost regardless.
Extensions add storage.
As mentioned above, extensions add bloat to the resource itself. This makes it difficult to manage the storage costs associated with two copies of the data. As we looked at ways of storing extensions outside of the resource a more elegant solution presented itself.
Investigating Arson
FHIR introduces the concept of the Provenance resource. The HL7 website describes the Provenance resource as:
“Provenance of a resource is a record that describes entities and processes involved in producing and delivering or otherwise influencing that resource. Provenance provides a critical foundation for assessing authenticity, enabling trust, and allowing reproducibility….”
One of the key features of Provenance is that it can contain references to other resources in its “entity” element. These links enable us to link two FHIR resources together via their Provenance. That leads us to our solution to the problem. We can store an original copy of the resource and reference it from the Provenance of the new resource.
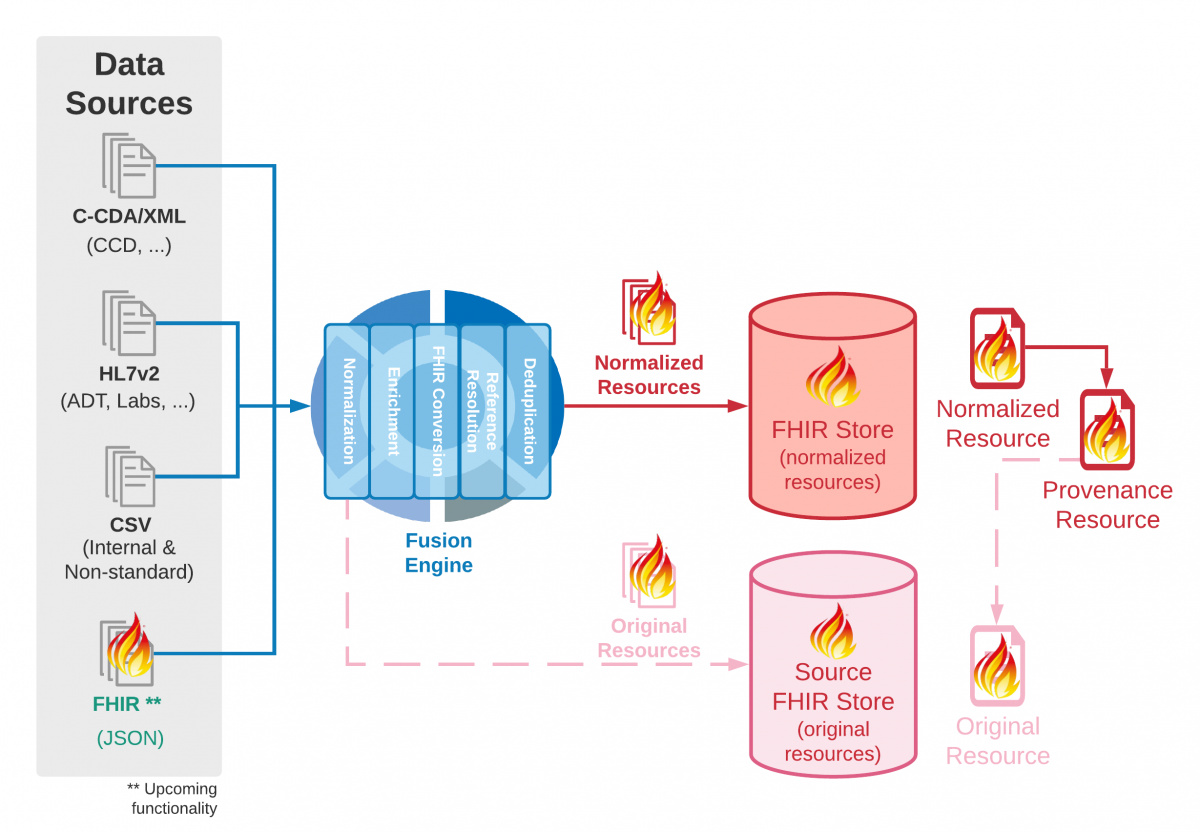
Provenance Lights the FHIR
The solution that we devised stores original FHIR resources with their codes and values intact. These resources are stored in a separate store, that can be offloaded to a cheaper solution. We then include links within the Provenance of the normalized resource to that original. Consumers of the FHIR resource can then choose whether to fetch the Provenance with the resource and then whether to follow the link to the original resource. But when they get that original resource, it is in the form of a resource and can be easily consumed.
Let’s look at how this solution solves our problem:
Providing original codes/values in a consistent way.
By embedding this in the concept of Provenance and utilizing resources, we provide a consistent way of both fetching and viewing the data. For all resources, the user can trace through the Provenance to the original. When they retrieve that original it is in a form that is a known standard. There is no guessing what the fields mean.
Preventing bloat in the data.
FHIR provides a standard way to include Provenance, or not, when fetching resources. For example:
- returns all the observations for a given patient without the Provenance recourses
- returns the same observation with the Provenance recourses included
It is completely up to the consumer of the API to decide how much data they want to receive. If the use case does not call for original codes / values, then there they are simply not requested and consume no bandwidth.
Flexibility in storage.
By storing original values in their own store, we have many options for storage media . Because the retrieval of the original resource will be primarily through references from the Provenance, it is not necessary to index and make them searchable. Further, we anticipate that access to these original resources will often be a secondary activity, meaning that performance is less of a concern. This opens the door to storing this data in a cold storage solution that is dramatically cheaper than our primary data store.
Cooking with FHIR
At Diameter Health, we are excited about the future on FHIR. We believe FHIR has the potential to help us realize the promise of interoperability in healthcare. We have many educational resources available on FHIR which you can explore. That said, FHIR is an evolving standard, and we are eager to work with you to make it better. We would love to hear what you think on the solution presented here or on the future of FHIR in general. We can always be reached at info@diameterhealth.com.

